

اوبر چگونه از بیگ دیتا برای رشد استفاده می کند

در اوبر ، بیگ دیتا و علوم اطلاعات در قلب همه چیز است. اوبر با بیش از ۱۰۰ میلیون کاربر فعال ماهانه، ۳ میلیون راننده، ۱۰ میلیارد سفر، حضور در ۶۵ کشور جهان و درآمد ۲.۹۵ میلیارد دلاری در سه ماهه سوم سال ۲۰۱۸، یکی از سریعترین استارتاپ های دنیا از نقطه نظر رشد می باشد. با حل مسائل مربوط به زیرساخت های ضعیف حمل و نقل در برخی از شهرها، تجربه مشتری نامطلوب، ماشین های قدیمی، و مشکلات عدم قبول کارت های اعتباری و موارد دیگر اوبر توانسته است در “کمتر از ۵ سال” دنیای حمل نقل شهری را متحول کند و به یک برند قابل توجه در حل مشکلات مردم در صنعت حمل و نقل تبدیل شود.
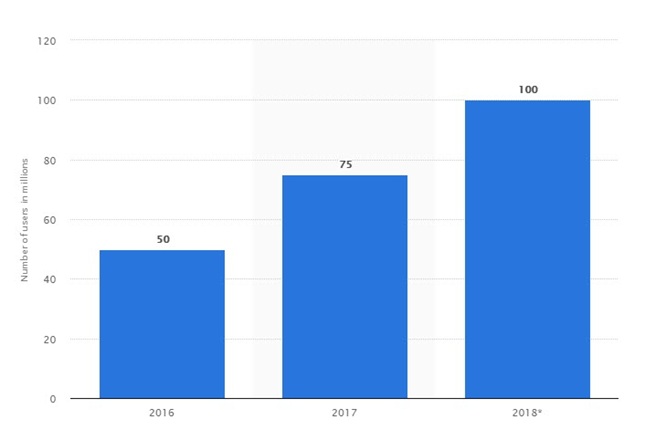
- نمودار شماره ۱ – رشد تعداد کاربر فعال ماهانه اوبر از سال ۲۰۱۶ تا ۲۰۱۸
اوبر بدون داشتن حتی یک ماشین با استفاده از دیتا تمام ماشین های تحت مدیریت خود را حرکت می دهد. Uber می تواند بوسیله آن افزایش قیمت، اتومبیل های بهتر، تشخیص سواری جعلی، کارت جعلی، رتبه بندی جعلی، برآورد قیمت ها و رای رانندگان را مدیریت کند. اصل بنیادین در اوبر big data principle of crowdsourcing است. داده های Uber در Data Hadoop جمع آوری و برای پردازش داده ها از Spark و Hadoop استفاده می شود. این داده ها از طیف وسیعی از انواع داده ها و پایگاه های داده مانند جداول پایگاه داده SOA و آپاچی کافکا می آیند.
اوبر تمامی اطلاعات مربوط به نقاط GPS ثبت شده برای هر سفر را در سیستم خود داراست و با استفاده از دیتابیس عظیم خود به محض اینکه یک کاربر درخواست ماشین می دهد با توجه به اطلاعات او بهترین راننده را در عرض ۱۵ ثانیه با پیشنهاد او Match میکند. آنها از دیتا های نگهداری شده از هر سفر برای پیش بینی تقاضای اتومبیل، تنظیم قیمت ها و تخصیص منابع کافی استفاده می کنند.
تیم تحقیقاتی داده ها در Uber همچنین تجزیه و تحلیل عمیق شبکه های حمل و نقل عمومی را در میان شهرهای مختلف انجام می دهد تا آنها بتوانند در شهرهای دارای حمل و نقل ضعیف تمرکز کنند و بهترین استفاده را از داده ها برای بهبود تجربه مشتری داشته باشند.
در این رابطه بخوانید: کلان داده در حوزه ترجمه برای بازاریابان
داده های دریافتی از رانندگان
اوبر در زمانی که رانندگانش هیچ مسافری را حمل نمیکنند نیز از اطلاعات دریافت شده از آنها برای تشخیص الگوهای ترافیکی، محل های حضور رانندگان، نظارت بر سرعت رانندگان، محاسبه پرداخت های تشویقی به رانندگان و اینکه آیا آنها به صورت همزمان برای شرکتهای رقیب نیز کار می کنند یا نه استفاده میکند.
تجزیه و تحلیل داده های بزرگ در سراسر شرکت اوبر گسترده شده است .یادگیری ماشین، علم اطلاعات، بازاریابی، تشخیص تقلب و بسیاری موارد دیگر هستند که در اوبر بر پایه بیگ دیتا ها کار میکنند. یکی از استفاده های جالبی که اوبر از بیگ دیتا دارد این است که به رانندگان کمک می کند تا باز طریق یک نقشه حرارتی بهترین نقاط را برای قرارگیری انتخاب کنند تا در نهایت با تعداد سفر بیشتر سود بیشتری برای دو طرف حاصل شود.
بیگ دیتا و رضایت مشتریان
یک دیگر از استفاده های اوبر از بیگ دیتا ها بالا بردن سطح رضایت مشتریان و رانندگان از طریق ایجاد تجربه کاربری مثبت است. در این مورد اوبر صرفا داده های مشتریان و رانندگان خود را ذخیره نمی کند بلکه می کوشد از این داده ها به صورت Real Time برای ایجاد تجربه مثبت و حس بهتر در مشتریان و رانندگان استفاده کند.
کلان داده ها و قیمت گذاری در اوبر
علوم داده قلب الگوریتم افزایش قیمت اوبر است. یک مدل قیمت گذاری داینامیک در قلب سیستم اوبر وجود دارد که این الگوریتم با توجه به شرایط مختلف در لحظه و با توجه به دو فاکتور منطقه جغرافیایی درخواست ومیزان تقاضا در آن لحظه برای یک سفر قیمت گذاری میکند، همچنین آنها با استفاده از تحلیل های رگرسیونی میزان تقاضا در هر منطقه را پیش بینی می کنند و از این طریق مناطق شلوغ را مشخص کرده و با کمی بالا بردن قیمت، رانندگان بیشتری را ترغیب به خدمات دهی در آن مناطق میکنند. موضوع بسیار مهم در این زمینه این است که اوبر سعی کرده است این الگوریتم طوری عمل کند که با این حال که افزایش قیمت وجود دارد ولی مسافر سفر خود را کنسل نکند.
اتفاق بسیار مهم دیگری که اخیرا در اوبر رخ داده است این است که دانشمندان داده این شرکت تلاش دارند با استفاده از روش های یادگیری ماشین میزان تقاضا را پیش بینی کنند تا از این طریق بتوانند توازن بین عرضه و تقاضا را تا حد زیادی حفظ کرده و در نهایت از بالا رفتن قیمت ها و اثر الگوریتم افزایش قیمت بکاهند. البته اوبر هنوز به صورت رسمی به کارگیری این سیستم را تایید نکرده است.
کلانداده ها و بحث زمانبندی در اوبر
بخش دیگر استفاده از الگوریتم ها در اوبر تخمین مدت یک سفر و یا مدت زمانی است که یک راننده به مسافر خواهد رسید که این موضوع با استفاده از تحلیل داده های محل سوار شدن و پیاده شدن مسافران انجام می پذیرد. یک موضوع جالب در زمینه استفاده از الگوریتم های Matching در اوبر این است که این سیستم در زمان درخواست مسافر، نزدیکترین راننده را با توجه به زمان رسیدن راننده به مسافر تعیین می کند و نه فاصله فیزیکی بین راننده و مسافر. همچنین منابع داده ای خارجی مانند وضعیت حمل و نقل عمومی نیز در برنامه ریزی های اوبر تاثیرگذار هستند.
تکنولوژی های تحلیل داده مورد استفاده در اوبر
پایتون زبان برنامه نویسی اصلی علوم داده در Uber است و به طور گسترده توسط تیم Data Uber مورد استفاده قرار می گیرد. معمولا در اوبر از ماژول های NumPy، SciPy، Matplotlib و Pandas استفاده می شود. تیم Data Ober گاهی اوقات از زبان های برنامه نویسی R، Octave یا Matlab برای ایجاد نمونه های اولیه یا پروژه های داده ی علمی استفاده می کند ولی برای بحث پیاده سازی های اصلی پایتون زبان مورد استفاده است. ابزار D3بیشترین کاربرد را در زمینه مصور سازی داده ها در اوبر دارد و پرکاربردترین فریم ورک SQL در اوبر Postgres است.
سخن پایانی

اوبر با استفاده از اطلاعات سرویس های دیگر خود مانند UberFresh و UberRush که به ترتیب برای تحویل مواد غذایی و بسته ها استفاده می شوند و ترکیب این اطلاعات با اطلاعات شخصی کاربران خود در حال تبدیل شدن به اَبَر کمپانی ای است که پیشرانه اصلی آن داده ها هستند.
