داده پرت یعنی چی؟ و چرا وجود دارد؟

داده های پرت (outliers) داده هایی هستند که در فاصله غیر نرمالی از سایر مقادیر هم گروه خود قرار دارد و فاصله زیادی از آنها دارند.
علت داده های پرت در دیتاست چیست:
- خطاهای ورود داده (خطای انسانی)
- خطای اندازه گیری (خطای ابزار)
- خطای تجربی (خطای اجرای تجربی یا استخراج داده)
- خطاهای عمدی
- خطای پردازش داده
- خطای نمونه برداری (استخراج یا تلفیق داده از منابع گوناگون یا نادرست)
- طبیعی (خطا رخ نداده، داده های نوظهور)
تفاوت داده پرت و نویز:
نویز با داده پرت متفاوت است. نویز داده نادرستی است که ممکن است نزدیک به داده های درست باشد. outliers، داده ایی است که از داده های دیگر بسیار متفاوت است. بسیار از اوقات داده های پرت نویز هستند اما گاهی داده های درست هم می توانند داده پرت باشند. برای مثال، فرض کنید داده های مربوط به درآمد ماهیانه مربوط به ۱۰۰ نفر شامل بیل گیتس را داریم. در این حالت میانگین درآمد این صد نفر به صورت میلیونی خواهد بود. داده مربوط به بیل گیتس داده درست اما پرت است. در حالی نویز داده ایی پوچ، غلط و غیر مفید است.
انواع روش های مواجهه با داده های پرت:
در هنگام شناسایی outliers باید به دو سوال پاسخ بدهیم:
- چه تعداد ویژگی یا متغیر در شناسایی داده های پرت به کار گرفته می شود؟ تک متغیره یا چند متغیره. در روش تک متغیره، در هر زمان یک متغیر برای شناسایی داده های پرت مورد بررسی قرار می گیرد اما در روش چند متغیره، در هر زمان چند متغیر مورد بررسی قرار می گیرد.
- آیا فرضی در مورد توزیع مقادیر ویژگی های انتخاب شده وجود دارد؟ پارامتریک یا غیر پارامتریک. در روش های پارامتریک فرض بر این که داده ها از یک توزیع اصولی مانند توزیع نرمال پیروی می کنند اما در روش غیر پارامتریک این فرض وجود ندارد.
برخی از پرکاربردترین روش های شناسایی داده های پرت عبارتند از:
- تحلیل مقدار حداکثری یا z-score (پارامتریک)
- مدلسازی آماری و احتمالاتی (پارامتریک)
- مدل های رگرسیون خطی (PCA, LMS)
- مدل های مبتنی بر مجاورتی (غیرپارامتریک)
- مدل های تئوری اطلاعات
- روش های شناسایی خطای با ابعاد بالا
در زیر به بررسی دو روش پرکاربرد شناسایی داده پرت یعنی z-score و Dbscan می پردازیم:
این مطلب را نیز بخوانید: مهندسی داده چیست وچگونه یک مهندس داده شویم؟
تحلیل مقدار حداکثری یا z-score:
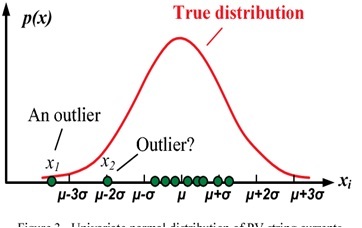
z-score روشی است که برای شناسایی داده های پرت مورد استفاده قرار می گیرد و از روش های پارامتریک شناسایی داده های پرت می باشد. زمانی که داده ها از توزیع نرمال یا گوسی پیروی می کنند، z-scoreمعیاری است که نشان می دهد که یک داده چند برابر انحراف معیار از میانگین فاصله دارد. بسیاری از متغیرها از توزیع نرمال پیروی نمی کنند، بنابراین نیاز به مقیاس بندی (scale) کردن این متغیرها وجود دارد. بعد از مقیاس بندی متغیرها، z-scoreهر داده از فرمول زیر محاسبه می شود:
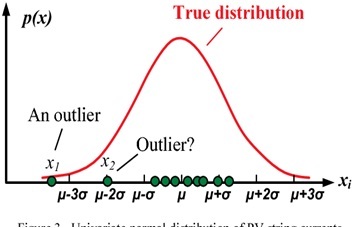
زمانی که z-scoreبرای هر نمونه در دیتاست محاسبه شد، حد آستانه ایی برای انحراف معیار مشخص می شود که می تواند مقادیر ۲.۵,۳,۳.۵ و یا مقادیر دیگر باشد. اگر حد آستانه ۳ در نظر گرفته شود، داده هایی که به فاصله ۳ برابر انحراف معیار از میانگین فاصله دارند، به عنوان داده پرت شاخته می شوند و از دیتاست حذف می شوند (مانند شکل زیر). z-score گرچه روش ساده ایی است، اما هنوز هم روش قدرتمندی در شناسایی و حذف داده های پرت است اگر داده ها از توزیع نرمال پیروی کنند و همچنین فضای ویژگی ابعاد کوچکی داشته باشند.
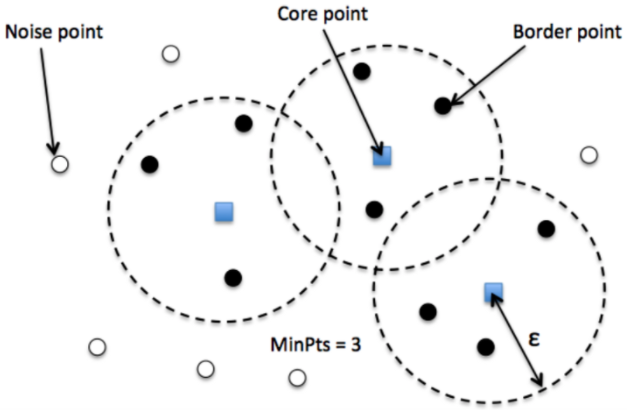
الگوریتم Dbscan:
الگوریتم Dbscan یکی از روش های غیرپارامتریک شناسایی داده های پرت است. در یادگیری ماشین و تحلیل داده ها، روش های خوشه بندی ابزارهای مفیدی برای بصری سازی، درک بهتر داده و همچنین برای شناسایی داده های پرت می باشد. Dbscan یک الگوریتم خوشه بندی بر مبنای چگالی است و بر یافتن همسایه ها بر اساس چگالی (MinPts) بر روی کره ایی با n بعد با شعاع R متمرکز شده است. یک خوشه می توان به عنوان مجموع ماکسیمال نقاط متصل چگال در فضای ویژگی هاست.
این الگوریتم دارای دو پارامتر است:
- شعاع همسایگی (R): شعاعی که اگر تعداد کافی نقاط داخل آن داشته باشیم، می توان آن ناحیه را چگال بنامیم.
- حداقل تعداد همسایه ها (MinPts): حداقل تعداد نقاط داده که می خواهیم در همسایگی یک خوشه تعریف کنیم.
الگوریتم Dbscanهر نقطه را به یکی از سه نوع زیر تقسیم می کند:
- نقطه مرکزی (core point): نقطه ایی که در شعاع Rاز آن، حداقل باید MinPts نقطه (شامل خود نقطه مرکزی) وجود داشته باشد.
- نقطه حاشیه (border point): نقطه ایی که در همسایگی آن کمتر از MinPtsنقطه وجود داشته باشد یا از نقطه مرکزی قابل دسترس باشد (در فاصله Rاز آن قرار داشته باشد).
- نقطه پرت (outlier point): نقطه ایی که نقطه مرکزی و حاشیه نباشد.
مراحل الگوریتم DBscan:
- الگوریتم با انتخاب یک نقطه دلخواه در پایگاه داده آغاز می شود و تا زمانی که همه نقاط دیده شوند، ادامه می یابد.
- اگر حداقل MinPts نقطه در شعاع R نقطه مورد نظر وجود داشته باشد، همه این نقاط به عنوان قسمتی از خوشه در نظر گرفته می شود.
- خوشه ها با تکرار بازگشتی محاسبه همسایگی برای هر نقطه مجاور گسترش می یابد.
در شکل زیر الگوریتم Dbscan را با حداقل تعداد همسایگی ۳ را مشاهده می کنید.