

علم داده (دیتا ساینس) چیست؟

علوم داده یکی از مباحث روز دنیا است که با استفاده از کامپیوتر و فناوری اطلاعات شکل گرفته است. این حوزه اساسا متکی به علوم کامپیوتر میباشد. جذابیت علم داده به حدی است که امروزه در اکثر دانشگاههای دنیا دورههای تخصصی برای تدریس آن در نظر گرفته شده است. ضمن این که پژوهشهای زیادی در این زمینه رو به افزایش است. علم داده به دانشی اطلاق میشود که به استخراج دانش از اطلاعات و دادههای مشخصی میپردازد. این علم ترکیبی از ابزارهای مختلف، الگوریتمها و اصول یادگیری ماشین است. هدف علم داده را میتوان استخراج معنا و مفهوم دادهها و همچنین تولید محصولات داده محور از حوزههای مختلفی مانند آمار، ریاضی، مهندسی شناخت الگوها و… دانست. امروزه علوم داده در زمینه های مختلف علمی و کاربردی پزشکی، روانشناسی، علوم اجتماعی، بازرگانی و مدیریت، علوم پایه، مهندسی و … در حال پیشرفت است. داده همواره یکی از مهمترین داراییهای هر سازمانی بوده و میتوان ادعا کرد که در دنیای امروز، سازمانها بدون تصمیمگیری بر مبنای برنامههای استراتژیک داده محور قادر به ادامه حیات نخواهند بود.در این پست به تفسیر علم داده،کاربرد ها و مسیر یادگیری آن خواهیم پرداخت.
دیتا ساینس چیست؟
علم داده (Data Science) یک ترکیب از علوم کامپیوتر، آمار و دانش تخصصی در حوزه موضوعی مشخص است که به ما اجازه میدهد دادههای خام را تبدیل به دانش و اطلاعات قابل فهم و کاربردی کنیم. علم داده شامل فرآیندهای استخراج داده، تحلیل داده، مدلسازی و پیشبینیها، و نهایتاً ارائه تصمیمات مبتنی بر داده است در واقع هدف علم داده با توجه به هرم دانش (DIKW pyramid) رسیدن به خرد از داده است.
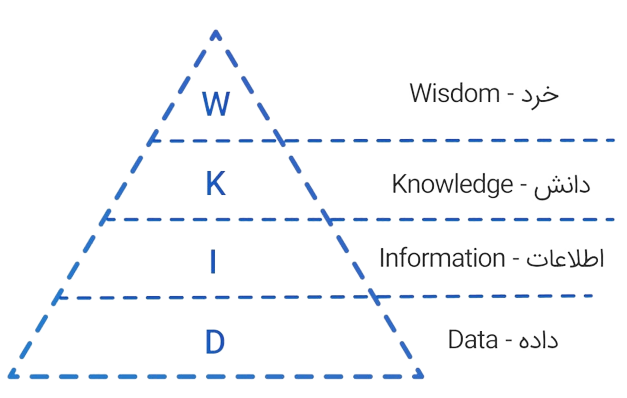
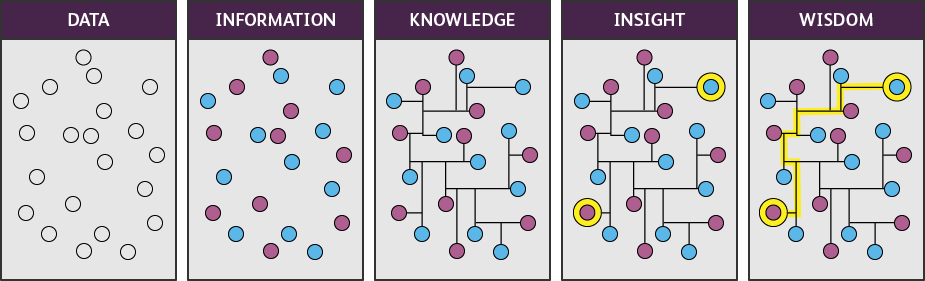
علم داده در شرکت ها و سازمان ها چه کاربردی دارد؟
علم داده به کسبوکارها امکان تحلیل و بهرهبرداری از دادههای ساختارنیافته را با استفاده از روشها و الگوریتمهای پیشرفته فراهم میکند. این تحلیلها به تصمیمگیران کمک میکنند تا تصمیمات بهتری را اتخاذ کنند، پیشبینیهای دقیقتری انجام دهند و به مشتریان خود پیشنهادات دقیقتری ارائه دهند. علم داده به کسبوکارها کمک میکند تا در مقابل رقبا رقابتی تر و بازاریابی بهتری داشته باشند و نهایتاً سودآوری خود را افزایش دهند.
۱. تحلیل پیشگویانه (Predictive Analytics):
علم داده کاربردهای بسیار در تحلیل پیشگویانه دارد. با استفاده از دادههای موجود، میتوان مدلهای پیشبینی ساخت که به تصمیمگیران کمک میکنند رویدادها و رفتارهای آینده را پیشبینی کنند. به عنوان مثال، در پیشبینی آبوهوا، دادههای از منابع مختلف مانند ماهوارهها، رادارها، کشتیها و هواپیماها جمعآوری میشوند تا مدلهایی برای پیشبینی آبوهوا و بلایای طبیعی با دقت بالا ایجاد شوند. این کمک میکند تا اقدامات لازم در زمان مناسب انجام شود و از خسارات احتمالی جلوگیری شود.
۲. پیشنهادات محصول (Product Recommendations):
علم داده به شرکتها کمک میکند تا پیشنهادات محصول به مشتریان خود ارائه دهند. این پیشنهادات با استفاده از دادههای مشتریان، تاریخچهی مرورگر، تاریخچهی خرید و ویژگیهای جمعیتشناختی ایجاد میشوند. علم داده به کمک مدلهای پیشرفته میتواند پیشنهادات دقیقتر و موثرتری را به مشتریان ارائه دهد.
۳. تصمیمگیری مؤثر (Effective Decision Making):
علم داده به سازمانها در تصمیمگیری مؤثر کمک میکند. به عنوان مثال، در مورد خودروهای هوش مصنوعی و خودران، این دادهها با استفاده از سنسورها مختلف مانند رادار، دوربین و لیزر جمعآوری میشوند تا خودرو بتواند تصمیمات حیاتی هنگام رانندگی را انجام دهد، مانند چرخش، توقف و افزایش سرعت. این تصمیمات با دقت بسیار بالا و در لحظه گرفته میشوند و از حوادث و خطرات جلوگیری میکنند.
مفاهیم و زیرشاخه های Data Science
- آمار و احتمالات (Statistics):
- آمار به تجزیه و تحلیل دادهها، استخراج اطلاعات معنیدار از آنها و ایجاد نتایج قابل اطمینان از طریق تکنیکهایی مانند میانگین، واریانس، توزیعها، و غیره میپردازد.
- احتمالات به مفاهیمی مانند احتمال، توزیع احتمال، رگرسیون، و تجزیه و تحلیل احتمالی دادهها میپردازد. این دسته از مفاهیم برای پیشبینی و تفسیر دادهها بسیار مهم است.
- یادگیری ماشین (Machine Learning): به توسعه مدلهایی که به طور خودکار از دادهها یاد میگیرند و توانایی پیشبینی و تصمیمگیری را دارند، اشاره دارد. این مدلها میتوانند در کاربردهای مختلفی مانند تشخیص الگو، پیشبینی، تصویربرداری، و موارد دیگر مورد استفاده قرار گیرند.
- یادگیری عمیق (Deep Learning): یک زیرشاخه از یادگیری ماشین است که از شبکههای عصبی عمیق برای تعامل با دادههای پیچیده و ساختاردهی شده استفاده میکند. این رویکرد به تحلیل تصاویر، پردازش زبان طبیعی، ترجمه ماشینی و مسائل دیگر در علم داده کمک میکند.
- بصریسازی (Visualization):یکی از اصول اساسی در علم داده است که به ایجاد نمودارها، نمایشها و چارتهایی جهت تجسم و تبیین دادهها و الگوهای مختلف در آنها میپردازد. بصریسازی به توسعه داشبوردها (Dashboards) و ابزارهای تجزیه و تحلیل داده برای ارتباط بهتر با دادهها و ارائه نتایج به تصویر میپردازد.
- پایگاه دادهها و مدیریت دادهها (Database Management):یادگیری نحوه طراحی، مدیریت و پرس و جوی پایگاههای داده از جمله MySQL، PostgreSQL، MongoDB و سیستمهای مدیریت داده بزرگتر مانند Hadoop و Spark بسیار مهم است.
- پردازش زبان طبیعی (Natural Language Processing – NLP):NLP به تحلیل و فهم زبان انسانی توسط ماشینها میپردازد و در برنامههایی مانند مترجم ماشینی، تحلیل متن، پرسش و پاسخ خودکار و سیستمهای تحلیل احساسات (Sentiment Analysis) کاربرد دارد.
- انتخاب و تجزیه و تحلیل ویژگیها (Feature Selection and Engineering):این مفهومها در یادگیری ماشین و یادگیری عمیق بسیار مهم هستند. آموزش نحوه انتخاب و ترکیب ویژگیها (ویژگیهای داده) برای بهبود عملکرد مدلها از اهمیت بالایی برخوردار است.
- یادگیری تقویتی (Reinforcement Learning):در این حوزه، مدلها بر اساس تجربیات خود تصمیمگیری میکنند و برای مسائلی مانند کنترل رباتها، بازیهای ماشینی، و بهینهسازی سیستمها کاربرد دارد.
- بهینهسازی (Optimization):بهینهسازی الگوریتمها و روشها برای تعیین بهترین پارامترها و مدلها در علم داده اهمیت دارد. مطالعه الگوریتمهای بهینهسازی مانند جستجوی گرادیانی (Gradient Descent) و الگوریتمهای تکاملی میتواند مفید باشد.
- انتقال یادگیری (Transfer Learning):این مفهوم به اشتراک دانش یک مدل آموزش دیده در یک وظیفه با وظیفههای دیگر اشاره دارد. این به افزایش کارآیی مدلها و کاهش نیاز به دادههای آموزشی برای هر وظیفه کمک میکند.
فرآیند های علم داده
فرایند علم داده (Data Science) به طور کلی شامل چند مرحله اصلی است که در زیر به تفصیل توضیح داده شدهاند:
- اکتشاف داده (Data Exploration): در این مرحله، دادهها از منابع مختلف جمعآوری و بررسی میشوند. این فرآیند شامل انتخاب و استخراج دادهها از منابع مختلف مانند پایگاههای داده، فایلها، وبسایتها، APIها و غیره میشود. همچنین تمامی دادهها برای تجزیه و تحلیل بعدی آماده میشوند.
- آمادهسازی داده (Data Preparation): در این مرحله، دادهها برای تجزیه و تحلیل باید تمیز شوند. این شامل حذف دادههای ناکارآمد، پر کردن مقادیر گمشده، تبدیل فرمتها، حذف تکرارها و انجام دیگر عملیات پیشپردازش است. هدف این مرحله ایجاد مجموعهای از دادههاست که برای مدلسازی و تحلیل مناسب باشند.
- برنامهریزی مدلها (Model Planning): در این مرحله، برای حل یک مسئله خاص، تعیین میشود که کدام تکنیکها و مدلهای آماری یا ماشینی باید استفاده شود. انتخاب متغیرهای ورودی، تعیین شاخصهای اندازهگیری موفقیت مدل، و تعیین استراتژی آزمون مدل نیز در این مرحله انجام میشود.
- ساخت مدل (Model Building): در این مرحله، مدلهای آماری یا ماشینی بر اساس دادههای آمادهشده ساخته میشوند. این شامل تعیین الگوریتمهای مورد استفاده، آموزش مدلها بر روی دادههای آموزشی و تنظیم پارامترهای مدل است.
- ارزیابی مدل (Model Evaluation): در این مرحله، مدلهای ساخته شده بر روی دادههای آزمایشی ارزیابی میشوند. این ارزیابی شامل اندازهگیری عملکرد مدل با استفاده از معیارهای مختلف مانند دقت (Accuracy)، معیارهای بازخورد (Precision و Recall) و سایر معیارهای مرتبط است. این مرحله به تصمیمگیری در مورد کیفیت مدل کمک میکند.
- عملیاتیسازی (Deployment): پس از ساخت و ارزیابی مدل، مدل نهایی برای استفاده در محیط تولید آماده میشود. این شامل اجرای مدل در سیستمهای واقعی، تنظیمات نهایی برای عملیاتیسازی و مدیریت مدل در محیط تولید است.
- ارسال نتایج (Communication of Results): در این مرحله، نتایج و یافتههای حاصل از تحلیل داده به ذینفعان ارائه میشود. این شامل توضیحاتی دربارهی نتایج، گزارشها، داشبوردها و تصاویر تجسمی است که به تصمیمگیری و اتخاذ تصمیمهای استراتژیک کمک میکند.
این مراحل به طور متناسب در فرآیند علم داده پیش میآیند و توسط تیمهای علم داده اجرا میشوند تا اطلاعات ارزشمندی از دادهها استخراج شود و به تصمیمگیریهای بهتر در موارد مختلف کمک کنند.
موقعیتهای شغلی در زمینهی دیتا ساینس چیست؟
حال که میدانیم دیتا ساینس چیست و چه کاربرد هایی دارد می توانیم به بررسی مفاهیم این حوزه و مسیر یادگیری آن بپردازیم
- تجزیه و تحلیل داده (Data Analysis): در این مرحله، دادهها تحلیل شده و اطلاعات مهمی از آنها استخراج میشود. این فرآیند شامل توصیف دادهها، تشخیص الگوها و روابط، و انجام آمار توصیفی است.
- مهندسی و تبدیل داده (Data Engineering): این قسمت از علم داده به تجمیع، تمیز کردن، تبدیل کردن، و ذخیره دادهها میپردازد. مهندس دادهها باید سیستمهایی را طراحی کنند که دادهها به سرعت و با کیفیت بالا قابل دسترسی باشند.
- یادگیری ماشین (Machine Learning): این زیرشاخه به استفاده از الگوریتمها و مدلهای ماشینی برای پیشبینی و تصمیمگیری بر اساس دادهها میپردازد. این تکنیکها به مدلسازی پیچیدگیهای داده و پیدا کردن الگوهای غیرخودکار کمک میکنند.
- یادگیری عمیق (Deep Learning): این زیرمجموعه از یادگیری ماشین به شبکههای عصبی عمیق متمرکز است. این شبکهها برای مسائلی که نیاز به تفسیر الگوهای پیچیده دارند، به خصوص در تصویربرداری و پردازش متن، بسیار مؤثر هستند.
- دادهکاوی (Data Mining): در این زیرشاخه، دادهها برای شناسایی الگوها، روابط و اطلاعات مخفی در آنها مورد استفاده قرار میگیرند. این به تجزیه و تحلیل دقیقتر و استخراج دانش از دادهها اشاره دارد.
- تجزیه و تحلیل اجتماعی (Social Network Analysis): در این حوزه، دادهها برای مطالعه و تحلیل شبکههای اجتماعی و ارتباطات انسانی به کار میروند. این تحلیل میتواند در مسائلی مانند تشخیص اجتماعات، تاثیرگذاری شبکهها، و تشخیص الگوهای اجتماعی مفید باشد.
- کلان داده(Big Data): این حوزه به مدیریت، تحلیل، و استفاده از دادههای حجیم و با سرعت بالا میپردازد. ابزارها و تکنیکهای خاصی برای کار با دادههای بزرگ و پیچیده مورد استفاده قرار میگیرد.
- دادههای ساختاری و ساختار نیافته (Structured vs. Unstructured Data): دادهها میتوانند ساختاری (مانند دادههای جداولی در پایگاهدادهها) یا نساختاری (مانند متن، تصاویر، و ویدیو) باشند. تحلیل و مدیریت هر دو نوع داده مهم است.
- حریم خصوصی داده (Data Privacy): در علم داده، مسائل حریم خصوصی دادهها بسیار مهم هستند. تضمین حفظ حریم خصوصی و امنیت دادههای حساس از جمله چالشهای اصلی این حوزه است.
- تصمیمگیری تحت عدم اطمینان (Decision Making under Uncertainty): در مواقعی که دادهها ناکافی یا ناقص هستند، ابزارها و تکنیکهایی برای تصمیمگیری با اطمینان پایین مورد استفاده قرار میگیرند.
مسیر یادگیری دیتا ساینس
با توجه به کاربردهای مختلف علم داده در رشتهها و صنایع گوناگون، طیف وسیعی از دانشجویان و علاقهمندان نیاز به یک نقشه راه دارند تا بتوانند از صفر یادگیری این حوزه را شروع کنند و یک سیر مشخص و منظم برای یادگیری و توسعه مهارتهای خود داشته باشند. وبینار فانوس در واقع برای روشن کردن وانداختن نور در مسیر یادگیری علم داده برگزار شد اگر شما یک علاقهمند به دنیای علم داده هستید یا به دنبال شروع یادگیری در این زمینه هستید، این وبینار مناسب برای شماست. ما امیدواریم که این محتوا به شما در تعیین مسیر خود و به دست آوردن مهارتهای لازم برای موفقیت در علم داده کمک کند.
ما در جهاد دانشگاهی صنعتی شریف برای شما عزیزانی که علاقهمند ورود به حوزه علم داده(data science) هستید و میخواهید توانمندیهایتان را در این مباحث گسترش دهید مجموعهای از افراد خبره این حوزه را دورهم جمع کردهایم و برای کسانی که میخواهند در این حوزه وارد شوند یک دوره مسیر یابی شغلی را بر اساس مباحث روز در نظر گرفتهایم که در این دوره شما با عمده مباحث مطرح شده به خوبی آشنا میشوید و بعد از آن می توانید به راحتی مسیر شغلی خود را در حوزه علوم داده انتخاب کنید. همینطور در کنار آن، نقشه راه و همچنین تک دورههایی را به صورت جداگانه تدارک دیدیم که در هر کدام از آنها با عمق بیشتری به مباحث ذکر شده پرداخته میشود و آنها را تکمیل میکند.

1 دیدگاه