

انواع الگوریتم های طبقه بندی (Classification) در یادگیری ماشین

یادگیری ماشین یکی از حوزههای پرطرفدار در علم داده ها است که به کمک الگوریتمها و مدلهای آماری، ماشینها را قادر میسازد تا براساس دادههای ورودی، تصمیمهایی را بگیرند و پیشبینی کنند. یکی از بخشهای مهم در یادگیری ماشین، طبقه بندی است که در آن، دادهها براساس ویژگیهای خود به دستههای مختلفی تقسیم میشوند. در این پست وبلاگ، به بررسی انواع الگوریتم های طبقه بندی در یادگیری ماشین میپردازیم.
منظور از طبقه بندی (Classification) چیست؟
طبقهبندی یکی از روشهای اصلی در یادگیری ماشین است که برای تخصیص برچسب کلاس به نمونههای ورودی استفاده میشود. این روش به ما امکان میدهد براساس ویژگیهای نمونهها، آنها را در دستههای مختلفی قرار دهیم. به عنوان مثال، با استفاده از طبقهبندی میتوانیم تشخیص دهیم که آیا یک ایمیل اسپم است یا خیر. برچسبهای کلاس در اینجا میتوانند اسپم و غیر اسپم باشند و باید به مقادیر عددی تبدیل شوند، به این صورت که اسپم را با عدد صفر و غیر اسپم را با عدد یک نشان دهیم. مثال دیگری از طبقهبندی، دستهبندی کاراکترهای دستنویس به کاراکترهای موجود است.
دسته بندی انواع طبقه بندی
طبقهبندی دودویی(Binary Classification):
در این نوع طبقهبندی، دو دسته کلاسی وجود دارند که برچسبهای آنها معمولاً صفر و یک است. هدف طبقهبندی دودویی، تخصیص یک برچسب به نمونهها بر اساس ویژگیهای آنهاست، به طوری که نمونهها را به دسته مثبت یا منفی تقسیم کند.
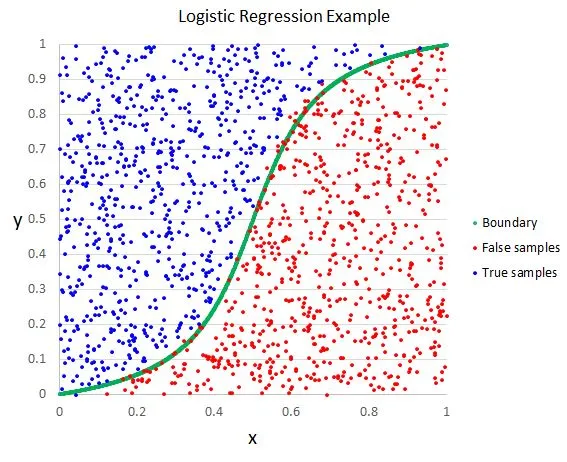
- رگرسیون لجستیک (Logistic Regression): رگرسیون لجستیک یک الگوریتم طبقهبندی است که برای مسائل طبقهبندی دودویی استفاده میشود. این الگوریتم بر اساس تابع لجستیک، احتمال تعلق یک نمونه به هر دسته کلاسی را محاسبه میکند. با تنظیم پارامترهای مدل، میتوانیم حد تصمیمی را تعیین کنیم و نمونهها را در دسته مثبت یا منفی قرار دهیم.
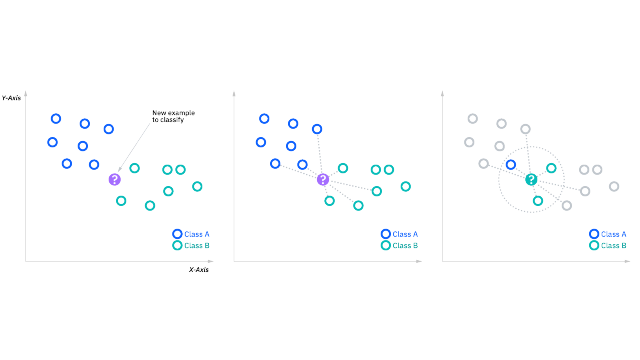
- نزدیکترین همسایه (K-Nearest Neighbors): الگوریتم نزدیکترین همسایه (KNN) نیز برای طبقهبندی دودویی مناسب است. در این الگوریتم، بر اساس فاصله نمونهها در فضای ویژگی، همسایگی آنها تعیین میشود. با تعیین تعداد همسایهها (K) و با محاسبه اکثریت برچسبهای همسایهها، میتوان نمونهها را در دسته مثبت یا منفی طبقهبندی کرد.
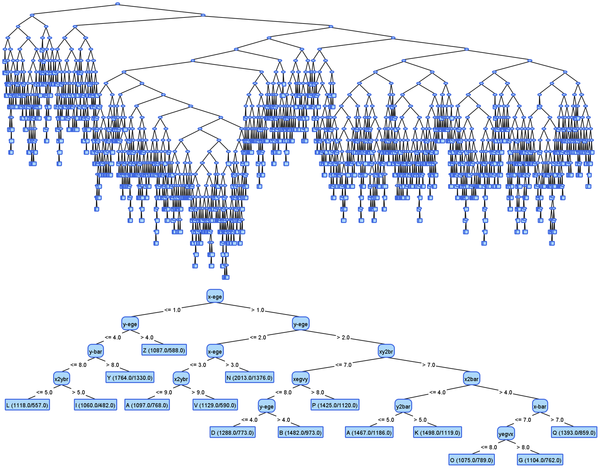
- درخت تصمیم (Decision Trees): الگوریتم درخت تصمیم نیز به خوبی در طبقهبندی دودویی عمل میکند. در این الگوریتم، با ساخت یک درخت تصمیم، سؤالاتی از ویژگیهای نمونهها پرسیده میشود و براساس پاسخها، نمونهها در دسته مثبت یا منفی قرار میگیرند. هر گره از درخت یک سؤال است که براساس پاسخ، نمونه را به شاخههای مختلف هدایت میکند تا به تصمیم طبقهبندی نهایی برسیم.
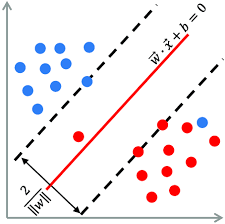
- ماشین بردار پشتیبان (Support Vector Machine): ماشین بردار پشتیبان (SVM) نیز یک الگوریتم محبوب برای طبقهبندی دودویی است. با استفاده از توزیع دادهها در فضای ویژگی، SVM سعی میکند یک سطح تصمیم بهینه را پیدا کند تا دادهها را به دسته مثبت یا منفی تقسیم کند. این سطح تصمیم، فاصله حداکثری از نمونههای دو دسته را داشته باشد.
- بیز ساده (Naïve Bayes): بیز ساده یک الگوریتم ساده و مؤثر برای طبقهبندی دودویی است. این الگوریتم بر مبنای قاعده بیز عمل میکند و با استفاده از احتمالات ویژگیها به شرط دستهها، احتمال طبقهبندی برای نمونهها را محاسبه میکند. با تعیین حد تصمیمی، نمونهها را در دسته مثبت یا منفی قرار میدهد.
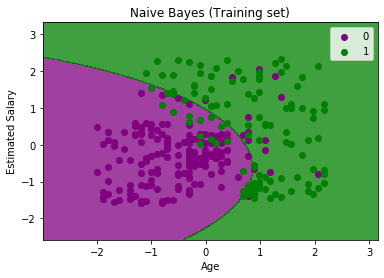
طبقهبندی چند کلاسه(Multi-Class Classification):
در این نوع طبقهبندی، سه یا بیشتر دسته کلاسی وجود دارد. هدف این طبقهبندی، تخصیص یک برچسب به نمونهها بر اساس ویژگیهای آنهاست، به طوری که نمونهها را در یکی از دستههای مختلف قرار دهد.به طور مثال، در شکل زیر دارای سه کلاس مختلف هستیم. مانند طبقه بندی چهره، طبقه بندی گونه های گیاهی و شناسایی کاراکترهای نوری. برخلاف طبقه بندی دودویی، نمونه ها، متعلق به طیف وسیعی از کلاس های شناخته شده می باشند. تعداد برچسب کلاس ها در بعضی از مسائل، ممکن است بسیار زیاد باشند. برای مثال، در سیستم تشخیص چهره، مدل پیش بینی می کند عکسی به یکی از ده ها هزار چهره موجود در سیستم، تعلق دارد یا نه.
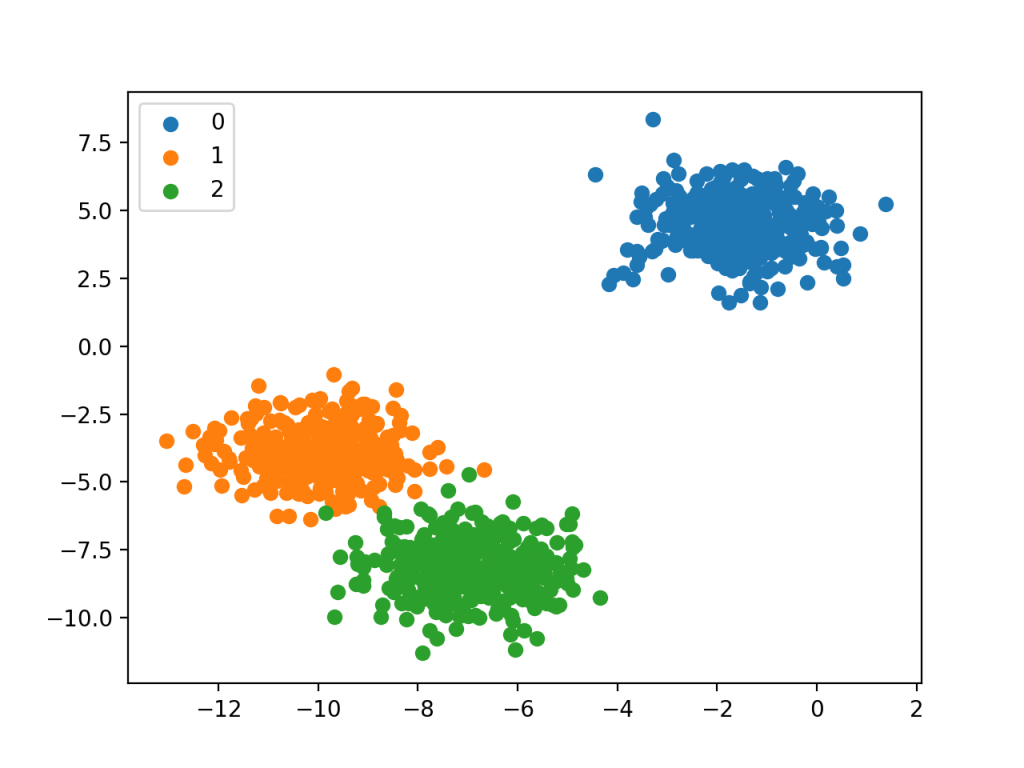
در طبقهبندی چند کلاسه علاوه بر الگوریتم های K-Nearest Neighbors -Decision Trees- Naïve Bayes الگوریتم های زیر نیز از محبوبیت بالایی برخوردار هستند
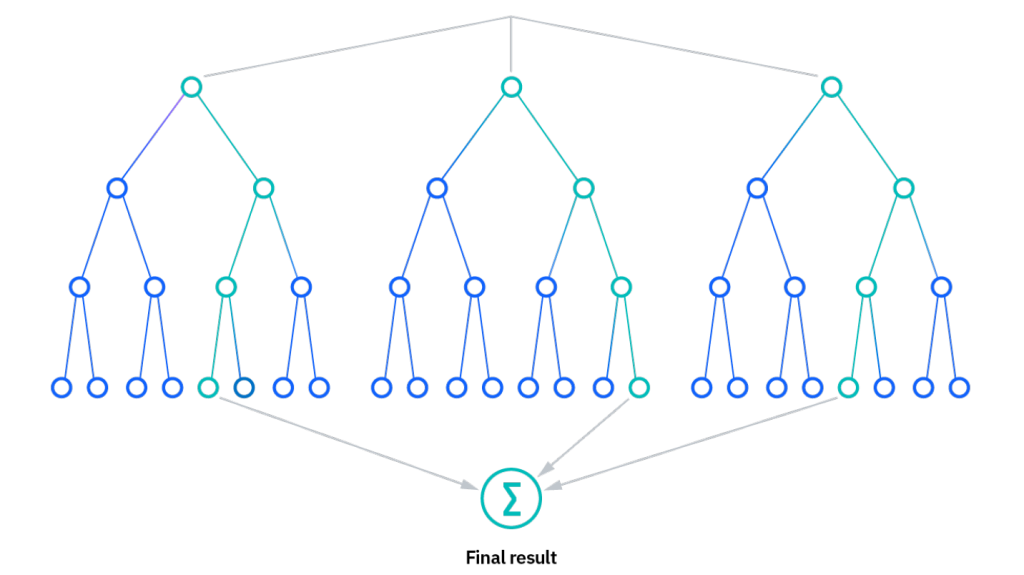
- جنگل تصادفی (Random Forest): الگوریتم جنگل تصادفی یکی از الگوریتمهای قوی در طبقهبندی چند کلاسه است. این الگوریتم بر پایه ترکیب تعدادی درخت تصمیم (Decision Tree) کار میکند. هر درخت در جنگل تصادفی به صورت مستقل و براساس زیرمجموعهای از ویژگیها و نمونهها ساخته میشود، و در نهایت با ترکیب تصمیمهای تمام درختها، طبقهبندی نهایی انجام میشود.
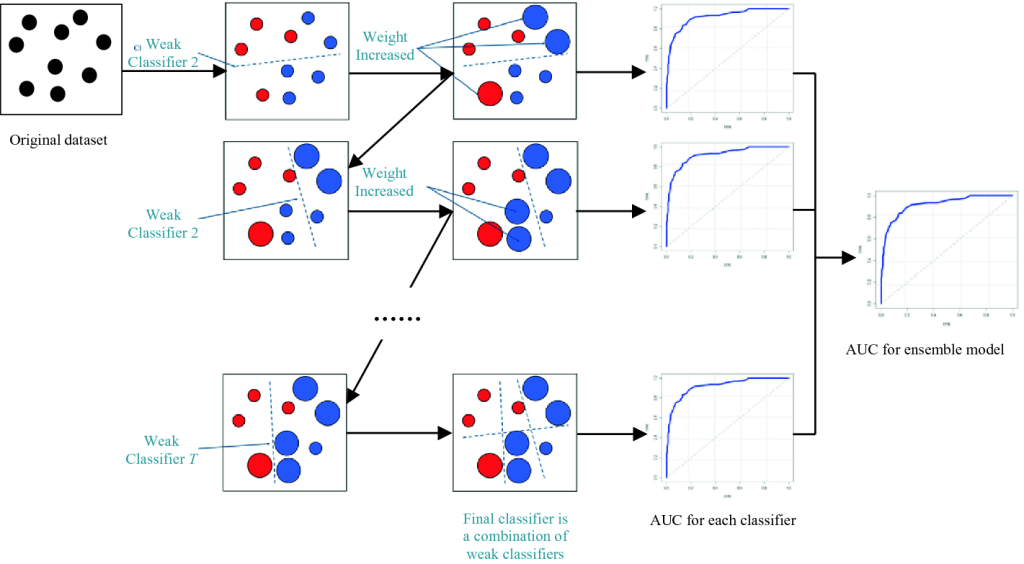
- گرادیان Boosting (Gradient Boosting): الگوریتم گرادیان Boosting نیز یک الگوریتم قدرتمند در طبقهبندی چند کلاسه است. این الگوریتم با ساخت تعدادی از مدلهای ضعیف (weak learner)، به صورت ترتیبی آنها را ترکیب میکند تا یک مدل قوی تشکیل دهد. هر مدل ضعیف تلاش میکند بر روی نمونهها خطای خود را کمینه کند و در نهایت با ترکیب تصمیمهای تمام مدلهای ضعیف، طبقهبندی نهایی انجام میشود.
همچنین مطلب تفاوت هوش مصنوعی، یادگیری ماشین و علم داده را نیز بخوانید.
تفاوت طبقه بندی چندکلاسه و چند برچسبی
طبقه بندی چند برچسبی، وظایفی هستند که در آن برای هر نمونه دو یا چند برچسب کلاس قابل پیش بینی است. در مثال طبقه بندی عکس، زمانی که یک عکس می تواند شامل چند جزء در تصویر باشد، یک مدل می تواند به پیش بینی چندین برچسب در عکس بپردازد مانند افراد، دوچرخه، سیب و غیره. در شکل زیر تفاوت بین طبقه بندی چندکلاسه و چند برچسبی را مشاهده می کنید.
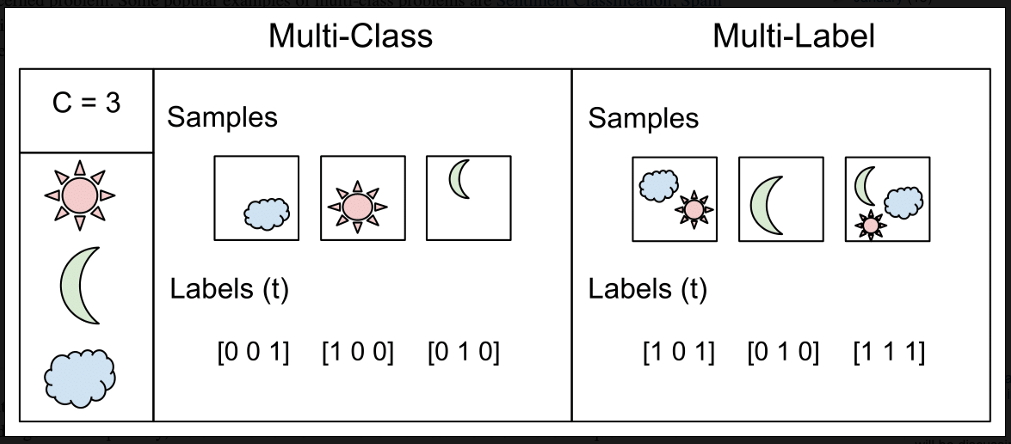
طبقهبندی چند برچسبی(Multi-Label Classification):
در این نوع طبقهبندی، هر نمونه میتواند برچسبهای متعددی داشته باشد. به عبارت دیگر، یک نمونه میتواند به چندین دسته کلاسی تعلق داشته باشد. این نوع طبقهبندی معمولاً در مسائلی مورد استفاده قرار میگیرد که هر نمونه میتواند برچسبهای متعددی داشته باشد.
الگوریتم های طبقه بندی دودویی و چند کلاسه نمی تواند به طور مستقیم در این مسائل به کار گرفته شوند، بنابراین باید از نسخه های الگوریتم های چند برچسبی استفاده کرد. مانند:
- Multi-label Decision Trees
- Multi-label Random Forest
- Multi-label Gradient Boosting
طبقهبندی نامتوازن(Imbalanced Classification):
در برخی مسائل طبقهبندی، تعداد نمونههای یک دسته کلاسی نسبت به سایر دستهها بسیار کمتر است. این مسئله را به عنوان طبقهبندی نامتوازن میشناسیم. در این حالت، الگوریتمهای طبقهبندی باید با دقت به این نامتوازنی رسیدگی کنند و نمونههای اقلیت را به خوبی تشخیص دهند.
همچنین بخوانید: داده پرت یعنی چی؟
از الگوریتم های مدل سازی خاصی که الگوریتم های یادگیری ماشین حساس به هزینه (cost-sensitive) نامیده می شوند، می توان برای داده های نامتوازن استفاده کرد. برای مثال:
- Cost-sensitive Logistic Regression
- Cost-sensitive Decision trees
- Cost-sensitive Support Vector Machine
در این پست وبلاگ، به بررسی و معرفی انواع الگوریتمهای طبقهبندی در یادگیری ماشین پرداختیم. هر یک از این الگوریتمها ویژگیها و کاربردهای خاص خود را دارند و به بسته به نوع مسئله و دادههای مورد استفاده، ممکن است عملکرد متفاوتی داشته باشند. در نهایت، بر اساس نیاز و شرایط مسئله، الگوریتم مناسبی را انتخاب کنید و بر روی دادههای خود اعمال نمایید.

1 دیدگاه